YOLO vs Multimodal AI Video Analysis — How VideoSenseAI Goes Beyond Object Detection

Meta Description
Discover how VideoSenseAi surpasses YOLO’s fixed object detection limits with dynamic, multi-class recognition. Compare accuracy, scalability, and real-world performance on a skiing video example.
Introduction
In the world of AI video analytics and computer vision, YOLO (You Only Look Once) has long been considered an industry benchmark. Fast, efficient, and lightweight — YOLO models power many real-time detection systems.
But as the needs of industries evolve — from security and retail analytics to sports performance and PPE compliance — the demand for multimodal, context-aware video understanding is rising. That’s where VideoSenseAI comes in — extending beyond object detection into AI summarization, metadata extraction, and multi-class recognition.
YOLO vs Our Multimodal Tool — Core Comparison
|
Feature |
YOLO (You Only Look Once) |
VideoSenseAI |
|
Model Type |
CNN-based object detector |
Multimodal transformer-based architecture |
|
Input |
Static frames or short videos |
Full-length videos, YouTube links, or live feeds |
|
Class Capacity |
Fixed — usually 80 (COCO dataset) |
Virtually unlimited — adaptive detection of hundreds of object types |
|
Output |
Bounding boxes + labels |
timelines, counts, summaries, CSV exports, GIFs, structured data |
|
Context Awareness |
Low — detects objects individually |
High — detects relationships and co-occurrences |
|
Customization |
Requires retraining for new classes |
Zero retraining — model adapts dynamically |
|
Processing Speed |
Extremely fast (real-time capable) |
Optimized for analysis + insights |
|
Output Usability |
Raw detection data |
Complete insight package — visualizations, summaries, and reports |
The Problem with Fixed-Class Models
YOLO, for all its speed, operates within a fixed class structure. Most YOLO versions are trained on 80 predefined classes (from the COCO dataset) such as person, car, dog, skis, backpack, etc.
This limits YOLO’s ability to:
✅Identify niche or context-specific items (like “goggles,” “helmet,” or “mountain slope”).
✅Adapt to new environments without retraining.
✅Understand relationships between detected objects (e.g., person + skis + mountain = skier scene).
VideoSenseAI, on the other hand, uses transformer-based architectures that learn semantic relationships, not just labels — allowing it to scale beyond 50+ or even 100+ detected elements per scene.
Real Use Case: The Skiing Video Test
Let’s put the two models to the test.
We analyzed the same skiing video clip using both YOLO and VideoSenseAI.
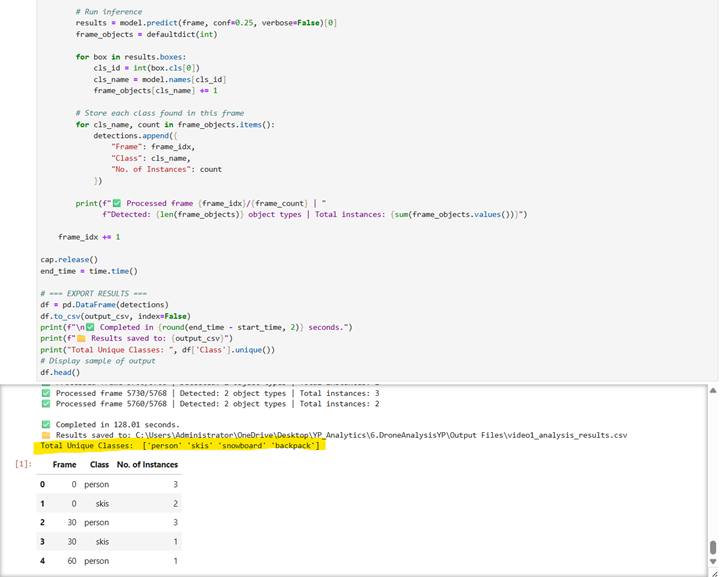
YOLO’s Detection Results
✅Detected only 4 object classes:
✅person, skis, snowboard, and backpack
✅Total detections: 4 unique items
✅Context: Recognized the skier but failed to identify gear, environment, or secondary objects.
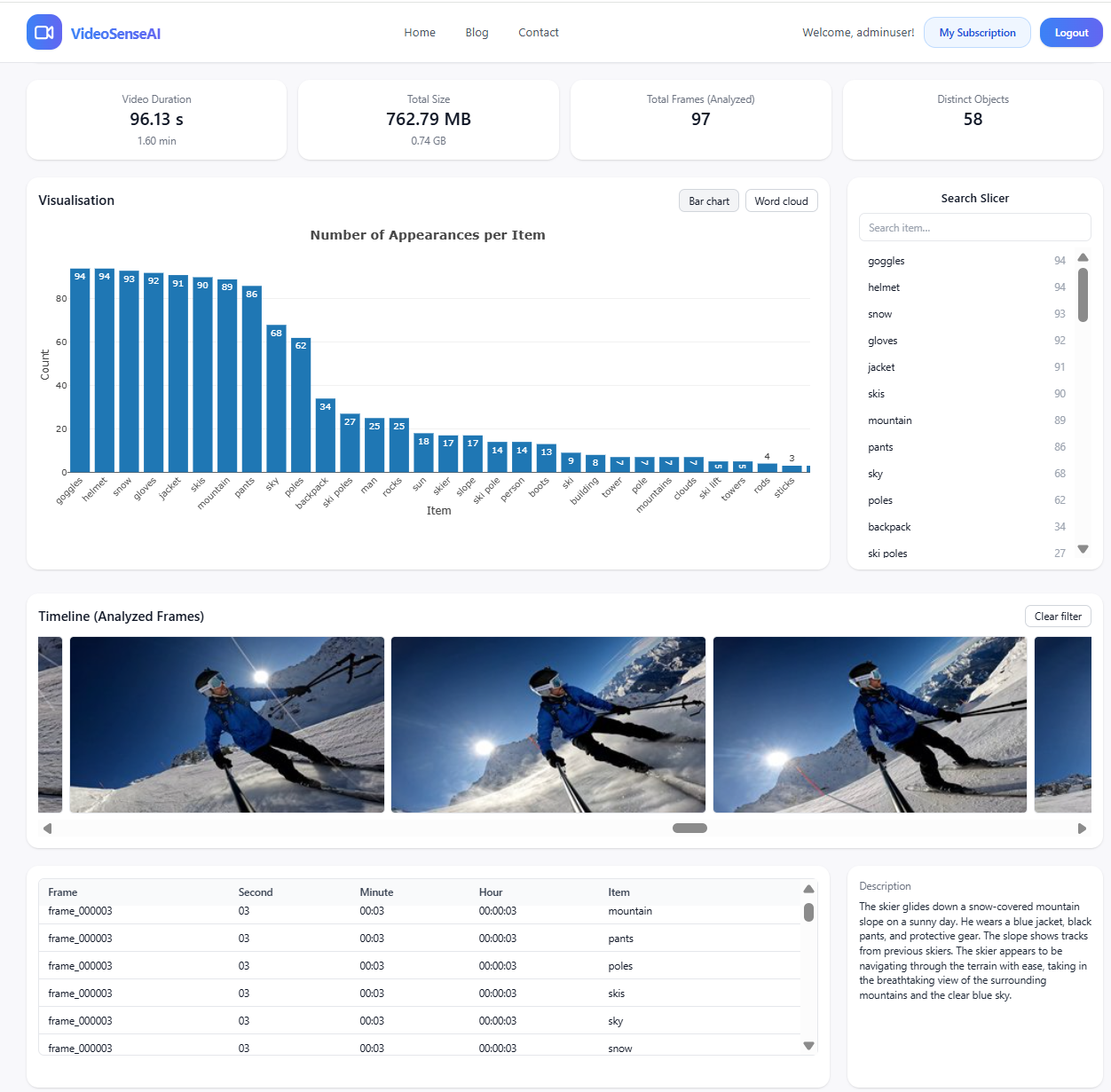
VideoSenseAI Detection Results
✅Detected 58 unique object classes including:
✅Safety & clothing: goggles, helmet, jacket, gloves, pants, backpack
✅Environment: snow, mountain, sky, slope, clouds, flags
✅Gear & objects: skis, poles, boots, antenna, sun, person
✅Generated full timeline, object count visualization, and AI-generated summary
✅Exported data to CSV and interactive dashboard
Key Takeaways
YOLO (You Only Look Once)
Pros:
✅Real-time detection performance
✅Low compute requirements
✅Excellent for embedded or mobile devices
Cons:
📌Limited to predefined object classes
📌No contextual understanding
📌No built-in analytics or summarization
VideoSenseAI
Pros:
✅Identifies dozens of additional objects dynamically
✅Provides timeline-based visualization
✅Offers AI-generated summaries and data exports
✅Includes search slicers and interactive dashboards
✅Fully multimodal (understands text + video + voice + metadata)
Cons:
📌Slightly slower than YOLO due to deeper processing
📌Requires short upload time for long videos
Why Multimodal Wins the Future
While YOLO is perfect for fast detection, it doesn’t tell you the story behind the data.
Our multimodal system combines object detection with AI summarization and data visualization, transforming raw footage into structured intelligence.
This means:
✅Detecting not just what is there, but why it matters.
✅Summarizing actions, environments, and correlations automatically.
✅Exporting analytics-ready insights in seconds.
SEO Keywords
yolo vs ai video analysis, multimodal video analytics, ai video detection, video summarization, computer vision, object detection, deep learning video analysis, real-time detection, transformer video model, ai video analytics platform, yolo comparison, video metadata extraction, video analysis dashboard.
Conclusion
While YOLO remains a powerful tool for object detection, its rigid architecture limits discovery. Our VideoSenseAI takes the next step — from detection to understanding.
It not only identifies more elements but also provides context, analytics, and actionable insights — redefining what AI video analysis can achieve.
Try it yourself.
Check this article on how VideoSenseAI wokrs: https://videosenseai.com/blogs/turn-video-into-searchable-data/
Related Guides
If you're exploring AI-powered video intelligence, you may also find these in-depth guides useful:
- What Is a Video Search Engine? How AI Turns Video Into Searchable Data
- How to Search Inside Videos for Objects, Words & Events Using AI
These resources explain how modern video indexing works and how you can turn long footage into structured, searchable data.